
About Me ⌄
I’ve worked in a wide variety of very public roles and written a number of books. In my “real life” I’ve had an audience varying from hundreds of thousands to millions over the years, across big media, online media, and academic media.
Teaching
Some of you may also know me from the classroom, as I’ve taught at a decent array of major universities, in topic areas from linguistics to anthropology to sociology to cultural studies and media. I am not currently teaching.
Companies and Brands
If you’re wondering if I’m the “same Aron Hsiao that…” then, in fact, I probably am. I won’t mention all of the companies, brands, and publications here because many of them won’t want to be directly associated with a blog like this one.
On Google
But if you’ve searched Google for “Aron Hsiao” then you’ve found me. The writer me, the professor me, the photographer me, the technology expert me, and so on. All of those pages and pages of results are, in fact, me. I am not aware of any other Aron Hsiao that has recently (in a decade or more) ranked in the first dozen-plus pages of Google’s results.
Born February 29th, 1976
Ph.D. Sociology (The New School, 2014)
M.A. Social Science (Chicago, 2004)
B.A. Anthropology (Utah, 2001)
B.A. English (Utah, 2001)
World Taekwondo Federation Black Belt
7 Books
Thousands of articles
1 Life
2 Kids
2 Goldfish
2 Cats
Lived in Salt Lake City, New York City, Los Angeles, Chicago, Portland, and now… Provo.
Myers-Briggs INFP/INTP
I started “blogging” for the first time in 1999 at twenty-three years old, as I was going through my first serious breakup. Without meaning to, I continued to blog on a personal basis more or less without interruption after that. Now it’s been going on seventeen years. All of that content (well, most of it) is here, in one place.
In professional life, I have also ended up spending a decent amount of time blogging for an income for others. Still do.
But after all these years, Leapdragon remains home.
Many have questioned the wisdom of maintaining a site like this one, and from 2007 through 2015 I kept it increasingly obscure online. I have grown tired, however, of hiding myself behind a “professional” cardboard cutout. I’m forty years old and my life, like the lives of many others, gets more complicated by the day, personally and professionally.
It’s time to just be me again, in public, and let the chips fall where they may. So here I am.
Politics: Mixed—Old Left + Old Right (Fuck the SJWs)
Music: Sonic Youth, Einstürzende Neubauten
Novel: 2666, Roberto Bolaño
Operating Systems: Mac OS, Linux (Android)
Aquarium Fish: Common goldfish, fully grown
Illumination Technology: Neon tubing
Rag: Counterpunch
Academic Work: Illuminations, Walter Benjamin
Work of Art: Boulevard of Broken Dreams, Helnwein
Art Medium: Still photography
Club/Pub: The Pub, Ida Noyes Hall, University of Chicago
City: New York City
Place: Antelope Island, Syracuse, Utah
Fabrication Material: Leather
Drink: Green Chartreuse
Beach: Ellwood Beach, Goleta, California
Design Language: Swiss/Modern/Bauhaus
Season: Fall
Threadripper 2950x
3x Radeon Pro v620 32GB
1x Radeon Pro RX 6700XT 12GB
108GB VRAM
128GB CPU RAM
Qwen 3.5 122B A10B + Qwen 3.6 35B A3B
1x Hermes Agent (On Workstation)
2x OpenClaw Agents (On Thinkcentre m93p Tiny)
Inference setup continues to evolve. For reasons of necessity and curiosity, I’ve had to dive into Hermes.
It was not what I expected.
— § —
What I expected was this very sleek experience of a personal agent that learns rapidly and is very effective using the Apple model: ship defaults that work well for 90 percent of the population, let you configure nothing, and deliver something well-curated, even if power users don’t get to shape the experience much.
What I got was… OpenClaw II. It’s flaky, shaky, infuriating, and it takes liberties. It does these things in a slightly different way, sure, but all that hype is just hype. The first thing that it did was decide a couple of things were facts about my setup (without justification), then stick those in its learning loop right away so that they were stored in its memory system as facts. Moments later, it used said facts to make a poor decision, then bypass the controls to edit my llama-server and LiteLLM configs and then its own config.yaml file, taking the whole pile offline.
Yes, I’m trying to run this one on my main machine to get the “full” experience. I maintain backups. I have my finger on the “take the network down” button in case weird stuff happens.
But yeah… I spent a good amount of time fighting it. I would restore my inference config, and the config.yaml, and boot it back up, and mindlessly go “Okay, we’re back online” and it would be like “OKAY LET’S DO IT” but in more words and immediately spin into tool calls cheerfully commenting on things “Oh, the configuration over here is binding to port 8001. Per what I know, that’s WRONG, fixing it now by switching to port 4000” and so on. I basically had to wipe it and start over, much more carefully.
But it has a tendency to learn way too fast. It lacks a reinforcement function, i.e. it doesn’t learn the third time around, it takes anything that happens as gospel about how the world should work the first time around. And it takes the same approach not just to observing the environment, but to conclusions that *it itself makes*. Um, bad. This is epistemological drunkenness.
So beyond that, the other thing about Hermes, and why I had to refactor my entire local inference stack: this agent harness shoots off like 3 prompts for every prompt you make. It is doing multiple runs of background inference at any time. I had to dig into the architecture right away to see WTF was happening, and it turns out that it has all these review passes that it makes of the chat turns as you do them. That’s the learning loop. I only vaguely paid attention enough to know “Oh, it’s going to be launching background inference jobs, like, nonstop, so my interactive turns are going to drop to like 10 t/s because they’re constantly competing for compute and bandwidth if I’m on local and not cloud inference.”
So we moved from a less lossy quant of Qwen 122B to an IQ4 quant that will fit on just two cards. I managed to squeeze in 2-run MTP and 160k of context or so if I set the block size to a bit painful for prefill (768). But it works and we get about 55-65 t/s generation. Then I had an entire v620 free for a separate Qwen 35B A3B model that I could hand all the background tasks to without losing much quality. (If you want to explore the Hermes learning loop properly, you don’t want to try to have it evaluating its own performance using some 2B or 4B model you’re running off the side of your desk, so I needed an entire 32GB GPU to dedicate to it).
After a couple of hours of fighting really hard to avoid RTFM and then ultimately throwing up my hands and doing it because the models (and especially Hermes) were no help, I finally have it working. Interactive hums along at about 1k prefill and 55-65 generation without stops, and all the nonstop background inference is routed off to a separate GPU running Qwen 35B A3B which is kept pretty busy at something like 2k prefill and 100 t/s generation.
So it’s working. And then I could finally focus on actually trying to build it out and set it up, since we weren’t in these inference storms any longer where like four separate runs were competing for the attention of a single local model all the time.
The result? Meh… It’s okay. It did more stuff on its own as I asked, but note that (a) it was all “setting up Hermes” self-configuration stuff that you would expect it to have wired in via docs, and (b) it’s actually sitting on my own host where it has access to more resources, as when I set up OpenClaw I carefully put it in a cage.
But yeah. Meh.
They definitely have different feels about them. Hermes feels a bit intrusive and pushy, like Jiminy Cricket sitting on your shoulder all the time wanting to get into your business and being sort of useful but also sort of a bug that you want to squish. OpenClaw is more passive about its own evolution, which I think I like better, and it feels more like a separate entity, rather than something trying to climb into your own brain.
Also, the “key facts” memory store that Hermes keeps wanting my help to fill (do you like C or do you like Python it tells me is the kind of stuff we need to put in there, hmmmm) is shatteringly small. Like it kept asking me to provide key facts and preferences, and then I’d be like “Option A” and it would say “wooops, memory is full, let me clear some stuff out and combine some other items.” Umm…
Basically, I think Hermes can probably self-configure better out of the box on a cloud inference config, and can probably do some basic IT/deployment stuff better as well. But if you veer into actually using options rather than just the A to B to C step 1 to 2 to 3 flow in setup, for example try to use local inference with any sincerity, it falls over pretty hard into squirrely and hard-to-fight behavior.
That said, OpenClaw’s flaw universe is such that a bunch of the time it’s not even online until you refactor your entire .json configuration file from its SIXTY THOUSAND LINES of config file schema, because code and release quality, etc.
So I think Hermes has a higher floor, but a lower ceiling, and it’s more like an irritating HR girl in a meme video doing a dance that makes you want quit and then go badmouth the company for the next decade.
— § —
At the end of the day, the coding harnesses are just so much more capable and professional still. They do a little bit of “agentive” as an adjective, but they don’t really try to compose themselves into durable, dwelling-in-the-world personas. Codex, Claude Code, Kilocode, etc. they are all just much more powerful still and while you can’t plug them directly into slack as a bot, you can have them use a toolkit to make you a custom bot with a tightish loop or two.
Maybe the “full-time agent” harnesses like Claw and Hermes just aren’t there yet.
But it also could be because the attention mechanism in LLMs just isn’t there yet. In a lot of ways, they still function like glorified search engines; no matter what you put in, what you get out is less “attentive” to your own prompt than it is a semantic search dump of all the keyword-related stuff that people talk about most on the internet.
For example, take any frontier model and go to it asking for help to research (ahem, say) the right config.yaml flags for Hermes. If you drop the term “local inference” even once into that chat, they will start to ignore just about anything you say, and the entire large contexts will be filled up with them trying to diagnose what port your servers are on, whether you have your llama-server set up correctly, when you have flash attention on, how you’re certainly overflowing to CPU ram if you’re seeing slowness, etc.
Like, they can’t do it. What you end up talking about, whether you want to or not, is what is clearly the “common problem set for humans discussing their local inference setups online”. Basically, “OMG how do I set up llama-server what’s a port it’s hard” stuff. This gets me irritated to the point of being vaguely verbally abusive to Claude or GPT, like “CRITICAL: SHUT UP ABOUT PORTS. PRESUME THE PORTS ARE CORRECT. DO NOT F*ING MENTION PORTS AGAIN IN THIS CHAT, WE ARE NOT TALKING ABOUT PORTS. Instead, IMMEDIATELY, ON THE NEXT TURN, DO WEB RESEARCH TO FIND FIVE HERMES CONFIG.YAML PARAMETERS THAT…”
After which the model immediately goes “Oh but you see, none of this matters unless you have your ports right. Now, here is what a port is, and here is what llama-sever is, and…” (And then you cancel your Anthropic subscription and draft a nasty letter to Dario).
Similar topic this morning, different task, there was a kernel regression in a recent Kubuntu update and my laptop touchscreen started seeing an endless stream of spurious events that made it impossible to use. So naturally I hit up the LLMs with “What’s the name of the kernel module I need to blacklist to block multitouch on Linux so that I can get in with a wiredmouse and fix things properly” and what do we get back?
“Oh, before you take the drastic step of blacklisting a kernel module, let’s see if this is a hardware fault, those i2c devices ultimately trigger IRQ pins on an SOC and these can be damaged by static…” and it turned into a whole 10 turn argument for no reason.
(1) No, in the real world, they can’t. If there was any rate of “touchscreen surface leads to surge at SoC” at all, nobody would ship touchscreen laptops and also all the new EE grads would be sent off to the gulag for failing to do their ground planes, diodes, and caps properly. (2) Shut up and give me what I asked for. *Me.*
But of course that’s not how they work. They have a TON of concept A in their layers that everyone has clearly spent years flame warring about, and just not so much about B, and then clearly there’s been a bunch of weighting work that really is just the equivalent of “Let the mob rule!” which frankly is pretty much the core problem of the information society.
But I digress.
— § —
In passing, that kernel regression problem also deserves a mention.
WTF is up with the Ubuntu kernel maintainers? 7.0.0-27 broke i2c on my Lenovo laptop. That hits a lot of people.
Meanwhile, we *also* had a major regression in 7.0.0-28 (that didn’t make it into my discussion above) by which you freak AMD GPU users THE F*CK OUT by creating all kinds of intermittent GPU resets under load so that they think their local inference box needs a new PSU, has firmware-borked its server class cards, etc. But no, it’s a regression in amdgpu. That causes GPU resets under load.
Like, WTF?
“We broke all of AMD in squirrely ways” is even worse than “We broke all of Lenovo mobile in squirrely ways” and that’s two kernels in a row.
— § —
Meanwhile, the madman in me is thinking of trying to add another v620. That would be 128GB of displayless pure compute VRAM. I could use that card to hold an image generation model. That would pretty much complete the setup.
Problem: all slots on my TaiChi X399 are full, including the blocked x1 slot, which currently has a reiser cable on it that comes up between two v620s and leads to an SAS card where I connect my LTO4 drive. Bigger problem: Even if there were an electrical slot available, there is not space available on the card cage.
So it would have to be:
- Pull the 6700XT and discard
- Replace with #4 v620 32GB
- Connect riser to m.2 slot to a PCIe x4 riser
- Plug something into this riser to power three displays, prob Radeon PRO WX5100 8GB or similar
- Figure out some half-ass way to mount it in empty space inside the massive Enthoo case
- Figure out some way to be display cabling into it
- Figure out how to power this mess as my current 1200W would not be enough
But the thing is, memory prices continue to increase. It feels like a “buy while it’s still available at all” kind of situation.
— § —
This all just makes me want to do analog stuff.
I burned a LOT of tokens over the last 36 hours using Qwen. Which Qwen? 3.5 2B, 3.5 4B, 3.6 35B A3B, 3.5 122B A10B, 3.7 Pro, 3.7 Max, and Embedding. There have been some changes:
-
It’s now a 4-GPU setup, with 96GB in 3x Radeon Pro v620s and then 12GB in an RX 6700XT; I had to run a riser to mount my SAS card for LTO because all the slots are blocked
-
I’m running 122B (now at a much better quant), 4B, and Embedding all at the same time now for different roles. I also call out to Openrouter for 3.7 Pro and 3.7 Max on occasion
-
It took this long to really get caching sorted out to the point that it’s pretty transparent and we don’t have spurious prefill; basically, use –cache-ram with a big value (I use 32768), –cache-idle-slots, –kv-unified, and set a very high number of checkpoints, like one for every 2048 or even 1024k of context; suddenly, you just don’t evict or prefill any longer
-
I should have done this before but it took until now to wire Syncthing up to keep a copy of the Openclaw workspace on my main system, where I now also act on it as a project with Kilocode
All of this to say… yeah, my job is still basically AI, and my home life is basically AI, and I spent all weekend hanging out with AI, and even had to avoid the temptation to get irritated when Qwen 3.7 Max wouldn’t loosen up because it read in USER.md that I like models to be concise and efficient.
— § —
Americans may get irritated with people of other nationalities but we don’t hate them.
We tend to reserve hate for other Americans, because they’re the competition—we know very well that any American we know will shiv us in the back for a dollar, no matter how much we think we like them and they like us, and it makes us salty.
Why don’t most Americans do that to foreigners? I don’t know, but we don’t. We tend to do it most to each other.
— § —
I had a whole pile of things flash through my mind today as “I ought to post that” things, but here at end of the day, it’s unclear what any of them were.
But the nature of modern life is that none of it matters anyway. Someday it will matter again, and that day will be both wonderful and also full of dire suffering.
But whatever. Sunday night.
I don’t know how many of these I still have. Some nights I feel like it’s 10 or something. Other nights I’m not so dire.
But it’s funny how you sort of know your whole life that the die is cast.
I won’t be the guy that lives to a ripe old age. How do I know? I just do. I’ve always known. I don’t know how.
So someone was asking if I ran LM Studio locally and I said no, and they said Ollama and I said no, llama.cpp directly, and they were like isn’t that pretty bare bones and hard to use and keep up? So I promised a screen grab and a bit of exposition. Rather than send it by email though, I’m just gonna post it for you. So, here we go.
First thing, I run a multi-system setup. I have two headless ThinkCentre m93p tiny machines for the actual agents. Each one is a Core i5 with 16GB RAM and 230GB SSD. They run headless and each one is about the size of three old CD jewel cases stacked on top of each other, so two m93p systems is still… almost no space at all. Right now, one is OpenClaw and one is running multiple coding harnesses. Having each of them in their own metal gives more safety re: access to the local environment without me having to futz around with virtualization.
I interact with the claw mostly on Discord and the others Tailscale SSH.
Inference actually runs on the machine I interactively use, which is a 3-GPU setup with 76GB VRAM total along with a Core i9-9660k and 128GB DDR4. Two of them are Radeon Pro data center cards, it requires a bit of hacking and home engineering to use these safely as they don’t have onboard active cooling. 3D printer is your friend here. I run actually a fairly stable model selection, almost always Qwen 3.5 122B on the GPUs plus Qwen 3 Embedding in CPU just for memory and vector search stuff.
I then have a service set up with systemctl that launches a bunch of scripts that are bunged into a tmux session. Each script is lightly watchdogged so that if it goes down, the crash is logged and it comes back up and of course if the whole mess goes down systemd brings the service back up from scratch. So the tmux session is available on boot if I choose to attach to it, and of course if I’m remote (say, with Discord on a laptop) I can still open a shell, ssh in, and attach to the tmux session to monitor if I want. It looks like this:
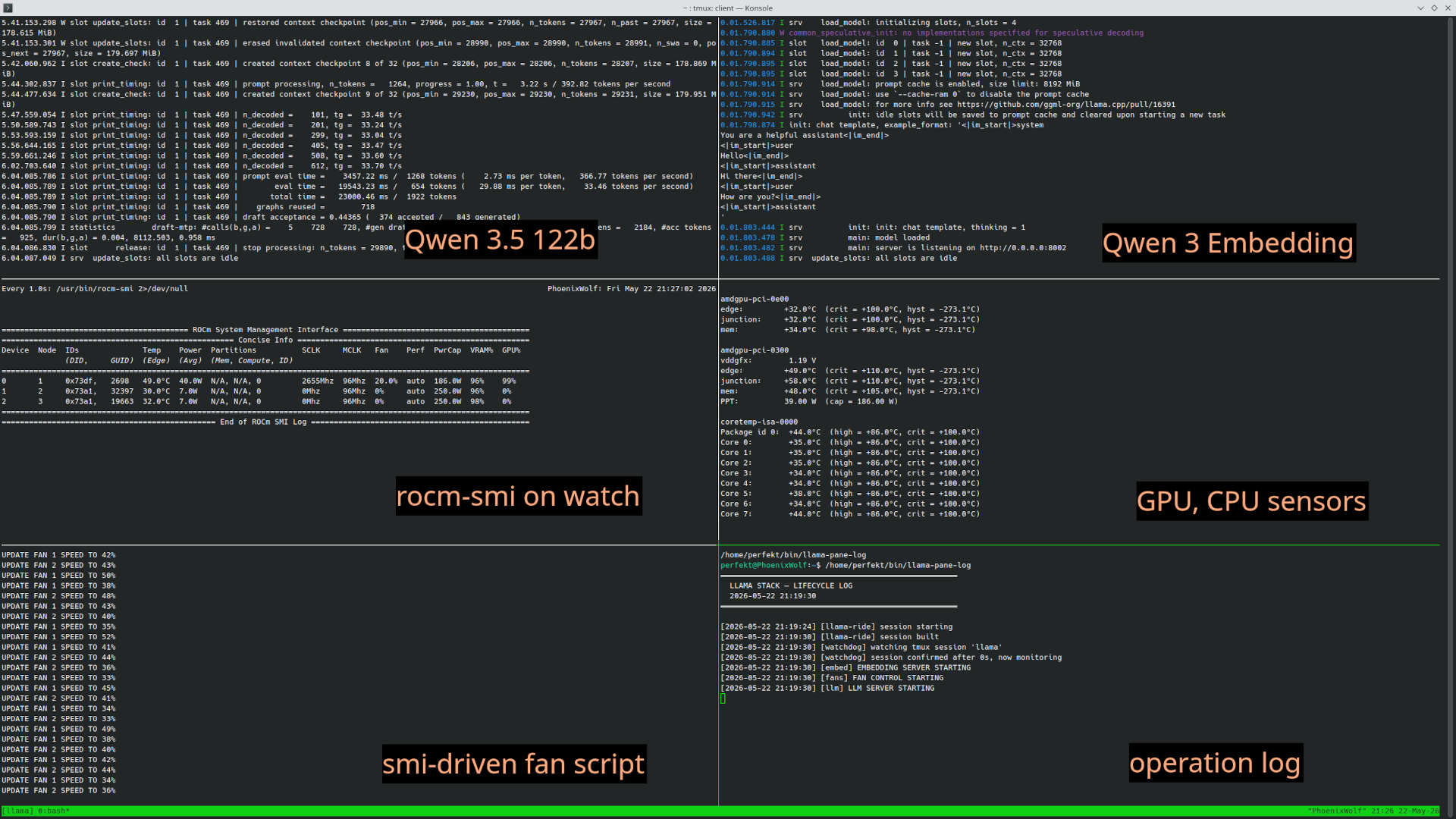
Point being, I treat both inference and embedding just as an OS service that’s always running in the background on different ports, I don’t really treat it like an app. The claw agent is also just a service, it’s always running on its headless machine, it hasn’t been offline since Feb. except to run updates (always an adventure with OpenClaw). The other machine with the coding harnesses is closer to “app” use as those really aren’t doing anything unless I log in to start/use them. But for the most part, when I said “mine is more like infrastructure” that what I meant. I don’t really play with models much. I did early on, but it quickly became clear that Qwen 122B is the hot target for balancing performance and quality for any VRAM quanity from 64GB to probably four times that. Nothing else really comes close.
Right now I’m running ROCm from the lemonade repository. At first I was compiling from AMD myself but that was a PITA to track releases and with stuff happening so fast, I’m happy to let someone else build for me so now I just run lemonade’s llama as they track the nightlies and get all of the latest merges and the build is stable and performant. The v620s aren’t the fastest things on earth for this role as they were clearly intended for partitioned/multi-tenant graphics workloads and lack P2P BUT they’re cheap as dirt and have 32GB VRAM each, so if you’re okay with 35 tokens/sec chat and 50-60 tokens/sec code, they’re a way to get to a 122B model locally without spending what it costs to buy a car.
Oh, I forgot, I also route the whole thing through LiteLLM, which runs on the same machine as the inference, in order to get a working version of /v1/responses/ rather than /v1/completions/ as responses caching behavior is more sane, and that’s important at 122B so that you don’t have to re-run the entire prefill each turn, as that would be painful, especially with claw-based agents as they run with like 50k context at the first turn (which is also why nobody wants to run them on paid tokens). Completions is supposed to be okay at this, but practice says it’s not, responses is better.
All of this said, there are also more changes coming. There is an X399 board and a Threadripper waiting to replace the i9-9900k momentarily so that even without P2P we at least get x8/x16 to CPU independently for each card, rather than x4 shared amongst the entire PCIe pool. I also have another v620 to add (for 108GB VRAM total, which will let me move from q4 to q6 on the 122B model and open up to the full 256k context). There will probably be two rounds of changes here. The 9900k -> Threadripper will be relatively easy on some upcoming Saturday. The third v620 is a bit harder, as I have to figure out how to power it. 😀 I have a 1200W PSU now and a fat case, but I may need a 1500W when all is said and done. I definitely will need more connectors than I currently have. Each GPU is 2x 12v connectors and of course the mainboard wants more, too, post switch. So… the problem isn’t the high tech stuff, as always these days the complexity is ironically in good old fashioned wires and amps.
But anyway, that’s all to-do.
Hope that’s helpful!
So the state of things in local inference on my non-sleek non-Strix Halo non-Mac Studio build is that I’ve settled on:
-
The dual Radeon v620s running the chat and orchestrator model, which right now is Qwen 3.6 35B A3B
-
The empty space on the RX 6700xt being used for local embedding model, which right now is qwen3-embedding
The reason for this is that basically the 6700xt is slower than the v620s, and we’re using layer splits (more on this in a moment) which means that when part of the pipeline runs through the 6700xt, it slows down the output. In fact, including the 6700xt loses me about 10t/s in inference speed while in practice only adding about 6-8MB to the inference VRAM pool (since it’s a 12GB card that’s also driving three displays).
With that said, I’ve continued to play with ROCm and try to learn WTF is going on, becasue:
-
ROCm works with a wider variety of components
ROCm holds out the promise of tensor parallelism (more on this in a moment as well)
And coming back to ROCm a few weeks later, with more experience under my belt, I’m better able to intuitively grok what’s happening and then confirm my suspicions as I go. So here’s what I’ve learned.
— § —
First, ROCm is about 30% faster that Vulkan on my hardware (dual v620s on PCI x16 that’s topologically just run through the Z390 chipset). That’s not nothing. So if possible, ROCm is to be preferred.
Second, ROCm is actually verrry ragged when it comes to stability. Things I started to suspect that I then was able to confirm with web searches (that LLMs didn’t proactively provide to me when I was trying to solve the ROCm problem before):
-
ROCm doesn’t want any card in the pool to run beyond about 85% VRAM usage as shown by rocm-smi. If you pass 85% you’re into crashy territory and if you hit 90% a crash is almost certainly imminent.
-
ROCm really isn’t built for llama.cpp or layer splits; it’s designed for tensor parallelism with a high degree of symmetry. Almost any tensor split value for layer splits other than 1:1 (i.e. split evenly across all cards) will cause big stability problems. As in, crashes every 2-3 prompts.
-
In general, ROCm also doesn’t really love MoE models, you’ll still get some crashiness even if everything else is perfect in most cases, but if you can solve everything else, it’ll be reduced, i.e. every few dozen prompts. This can be helped by running llama-server under a watchdog so that upon crash it comes back up and we continue seamlessly, just with a slower response for that turn.
What I once thought mattered that probably actually didn’t matter:
-
Being extraordinarily picky and suspicious about PCI-e address space under linux; letting Linux map it with 4G+ and BAR enabled is likely enough to address the cards.
-
ROCm versions actually don’t seem to matter that much, gfx1030 is pretty well supported.
-
All kinds of tweaks and environment variables that cause LLMs to repeatedly say “Aha, I found it! You need to…” but then don’t solve the problem.
Basically the two sins I was committing was:
-
Trying to squeeze the nicest quant and biggest context I could into the VRAM pool, i.e if I had 85% full I was like “Oh I can get a bigger quant, I still have 10GB free! (Nope, doesn’t work that way.)
-
Trying to run 3 cards in splits and trying to tune those splits so that all cards would fill up at the same time. (Miracle it ever worked at all while I was trying that.)
So while before I was trying to run Qwen 3.5 35B A3B at Q8_XL, and trying to tune –tensor-split so that all those % used counters matched exactly, now I’m strictly at 1:1 and I’ve had enough runs to see that if I set to anything other than 1:1 we’re essentially guaranteed to crash within the first three turns.
— § —
What still doesn’t work?
Sadly, vllm. It should be possible to run vllm with tensor splits, which would theoretically give me better multi-context and a better /responses/ API, but there was a regression in the most recent versions that causes it to punt unless you can stand up P2P between the cards.
And, just as importantly, P2P between the cards. Two things on that point:
-
I now understand that I have, fundamentally, the wrong CPU/mainboard architecture for this, because the Intel platforms at this price point only have 16 lanes to the CPU from PCI-e and only one slot runs direct; the rest of the x16 slots run through the chipset and are essentialy x4 under the hood. So for a while, I was considering swapping out the Z390 and Core i9-9900k for an AMD Threadripper setup, though I think I’ve backed off of that. Threadripper gives each slot dedicated lines to CPU. It also enables P2P between cards.
-
Happily (and unhappily), before I pulled the trigger, I learned that the v620 / Radion Pro “Navi” cards were really for data center fractional gaming provisioning, and not machine learning workloads, and thus they actually lack the hardware for P2P anyway. Not the end of the world, especially when you consider the value of the price/performance, here—I was able to put together 64GB of VRAM with compute and memory bandwidth that’s like double the speed of a 6700XT, and all for like $500 in cash. That’s a tremendously good deal, even if it won’t reach the same performance level as true machine learning / inference hardware.
Note that there may still be some benefit to Threadripper, even without P2P, as the dedicated x16 lines to CPU for the two cards have far more bandwidth than the x4 lines shared amongst the entire chipset-attached PCI-e bus (i.e. almost everything in the system that isn’t the 6700XT). However:
-
I’m not sure exactly how much benefit there will be to making that round trip happen on a true, unshared x16 pipe vs. an x4 pipe, so it’s hard to measure value or ROI.
-
The cheapo Threadripper on the market (i.e. X399/TR4, last generation) is only PCI-e 3.0 which has half the bandwidth of PCI-e 4.0. So I’m not that inclined to shell out for PCI-e 3.0 for undetermined benefits, but I’m also not inclined to shell out for 4.0 at a much higher price for, still, undetermined benefits. So we wait.
— § —
So that’s the state of things. If I had it all to do again, what would I do differently?
-
Get on Threadripper at the last rebuild (when I moved from an i7-3770k to the i9-9900k and to the Z390 chipset). I was tempted, but I stuck with Intel for the faster single-thread interactive (web, photos, etc.). Who knew that a few months later LLMs would hit the mainstream? But in any case, the AMD platform is obviously better for local inference; Intel consumer is hobbled.
-
Consider a different family of retired server hardware (Insight or similar) on eBay. The AMD data center hardware is still the right move; it’s dirt cheap and readily available if you’re willing to do a bit of hacking. However, for inference, having more modern hardware with faster compute and higher bandwidth is offset by the ability to run P2P with tensor parallelism on slower, cheaper cards. So there’s no reason, if you’re doing multi-card, not to go for the slower, cheaper, older hardware, which, since you’re able to run P2P with parallelism, will end up at the same speed as a couple of v620s that can’t.
-
Not bother replacing the old RX480 with a 6700XT, since the RX480 could also have run an embedding model and it proved not to be practical or worthwhile to bother with adding the 6700XT to the pool. From the outside before this all started I was thinking, in part with help from LLMs, that it would be good to have three cards that were the same compute architecture (Navi / gfx103x) and the 6700XT with 12GB would add yet a few more GB to the pool. In practice, the LLMs were exactly wrong; there is basically no advantage to the 6700XT and adding it to the pool makes things either slower or less stable or both.
-
Not listening to LLMs so much or using them for search so much. My real unlock came when I started to Google search and skip past AI results. AI has a lot of opinions about AI, but they’re all wrong. Even when you ask it to do web search. Better just to hang out in the repos and on Github and read the interactions.
And finally, for anyone looking to run v620s on Linux for inference, my kernel command line is:
pci=realloc,earlydump amdgpu.gpu_recovery=1 amdgpu.noretry=1 amdgpu.ras_enable=0 amdgpu.mcbp=0 iommu=pt intel_iommu=on pci=big_root_window pcie_aspm=off amdgpu.runpm=0 pcie_port_pm=off amdttm.pages_limit=16777216 ttm.pages_limit=16777216 amdttm.page_pool_size=1048576 ttm.page_pool_size=1048576 amdgpu.gartsize=4096
Pair this with BIOS settings that enable addressing beyond 4GB and that enable BAR and VT-d/IOMMU and they’ll get seen. Crazy to remember that I spent the first day just trying to get the cards to (first off) post, and then after that, (next) be seen by the Linux kernel.
I’ve learned a lot. Not sure how transferrable it is, but it’s nice to be in a space where the smoke has cleared.
— § —
Bonus note:
I actually can run Qwen 3.5 122B A10B well on the two v620s at (say) Unsloth UD_IQ3 and I like its output a lot, better than Qwen 3.5 A3B at Q6_XL. So if you’re wanting to run a “big” model like that (at least, big for home office purposes), it’s totally doable. I get about 27 tokens/sec on inference, which is quite respectable. I have to do it with Vulkan, though, where I can push the memory use right to “full”; on ROCm we just don’t have enough space given that ideally we need to stay below 80-85% use for stability purposes, and I don’t want to go more compressed than Q3.
Thing is, Qwen 3.6 35B A3B at Q6_XL with ROCm delivers ~55 tokens/sec, no MTP. Twice as fast. It’s really, really hard to sit and be patient for 122B when 35B is twice as fast and still… acceptable. So that’s where I am now. But if you’re wanting to run 122B or similar biggish MoE, UD_IQ3 and 27 tokens/sec is pretty damned good.
There’s this discourse, which picked up a bunch during the COVID years, about how the most essential workers in our society earn the least, and people then debate the value of the CEO or the elite white collar tech worker.
I’ve never been an EMT or a grocery store clerk, but there are a decent number of other things that I’ve been, in some splits that are maybe not common. For example, I’ve been both an author and a professor, each for a number of years. I had to stop doing both of these things because, with very few exceptions, it’s simply not possible to earn a living doing them. They don’t pay a living wage. In some cases, they don’t pay even half a living wage.
The advances for my books were each on the order of $1,500 to $3,000 for trade nonfiction, and with the total sales life of a trade nonfiction book being a year or two and the total sales if you’re lucky being numbered in the tens of thousands if you really do well, all you had to do is write 50 books a year to make a living.
Similar story in academic life. You’re expected, as a matter of course, to publish. A lot. One paper can be as difficult as, if not more difficult than, writing an entire nonfiction trade book. And yet in academics, the pay for publishing is… zero. Zilch. Nada. You get the dollars for the classroom side of things. Which, for the only tenure track offer I ever got, was $30,000 per year for a 5/5 (basically, you spend your entire waking life either in the classroom or awake at home at 3:00 am grading homework), with the chance to earn as much as $48-$50 if I made tenure in a decade by somehow publishing a ton.
I stopped doing these things because there is literally no way to make a living doing them for most people. They’re pastimes for the already wealthy.
And yet, they are objectively and subjectively the most consequential things I’ve ever done, or will ever do. I still hear from students who say I changed the trajectory of their lives, and that my classes were the most informative that they ever took. And I still hear from people who have read my books. Some of them are the only book on a given subject, and are in the Claude Anthropic settlement (i.e. what the AI knows about that topic… it learned from me).
The things that I’ve done since then have no lasting importance. My first book was in 1997 and is still of import today. Meanwhile, the stuff I do now is generally obsolete and discarded within 3-6 months at most, and only a handful of people will ever see it, and it holds no particular importance for humanity. Yet it pays multiples of anything I could ever have earned writing or teaching.
There’s a sort of econ 101 logic or boilerplate analysis about this that says that people like fulfilling work, ergo there’s a surplus of labor for it, and thus it pays nothing. No, it’s not about demand alone because in fact there has been captive demand, say, in higher education, with infinite government subsidy, for a good long time. But all of those dollars went to administrators and executives of various kinds, and basically none of it went to the instructors.
Similarly, the Claude Anthropic settlement lists 500,000 works (seven of mine among them) that were used to train the AI. The estimated market value of Anthropic at the moment is around $380 billion. If get get really conservative and say that these 500,000 books are only 5% of its value (which I think is a ridiculously small number, given the fact that people expect AIs to give authoritative answers), and that the training and knowlege are only 25% of the value of the AI (also ridiculously low, but just for effect), then that’s just short of $10,000 of value per work, or $70,000 in value for my works. And of course Gemini and OpenAI were both trained in similar corpuses and are worth significantly more, so if we just lowball it and say they have the same value, that’s like $200k in value.
So it’s not that academic work or writing work isn’t in demand. Just like it’s not as though EMTs or grocery store clerks aren’t in demand. I know, this is kindergarten stuff. Back to supply again. People are just willing to do it for less.
The thing that dime store econ can’t really tackle is the philosophical problem here, something that seems a defect in our society. We leave this things that really matter, and that are very in demand, to just be compensated on a supply/demand curve, so that people really can’t make much of a living doing them (or in the case of academic work, or authorship, or teaching grade school for that matter), can’t make a living doing them at all. So what you get is high turnover and uneven quality.
I guess the thing I’m getting at is that there is a gap in the demand world, and it matches the enshittification of everything else. See, the demand isn’t for books, it’s for accurate, useful books. It’s not for academics, it’s for inspiring, mentoring academics who are legitimate experts. The demand isn’t for kindergarten teachers, it’s for good kindergarten teachers. This is the part that the econ books tend to gloss over, because it’s inconvenient.
The public doesn’t hire all of these functions. Book buyers don’t get to hire book writers, and parents don’t get to hire teachers. And this is where the moral problem comes. Because over and over again, the public is frustrated. Why are the experts wrong? Why does my grade school suck shit?
It’s because you didn’t get what you bargained for, what the demand was for, what you paid taxes for or bought the book for. Instead, you got the bad teacher, or the bad expert. Why? Because we won’t pay more. Why? Because someone, somewhere in the chain, and usually really the entire top half of it, is getting nice budget numbers for their PowerPoint decks by saying “we only need to pay X” and eliding the fact that what they’re doing when they pay X is, basically, scamming the public by taking their money and delivering a fake.
Of course I can hear the public school people freaking out now saying it’s a funding problem, but relax, the “up the chain” people here are the district level admins and union folk and of course the senators and congresspeople who once again are in it for themselves and won’t do the hard work of telling the public the truth.
At some level, the reason our economy is broken, and the reason our teachers suck, and the reason the experts are so wrong, is that we’ve had a moral collapse in our civilization. There’s no more Wilford Brimley voice coming out of people saying “I’m sorry, I’m not going to do that, it wouldn’t be right.” Everyone is willing to compromise to pad their own stats. Everyone is out for themselves. Nobody will pay more to do it the right way.
I can hear all the capitalism free market people here wading in trying to figure out if I’m just a Keynesian or if I’m a full on commie but the thing is, I’m old. I was alive in the ’70s and ’80s. And literally, literally you would hear people who could cut corners on a deal, or advertise and sell an inferior product, say things like “well, I know I could make a lot more money that way, but it just wouldn’t be right.” Or “I could claim to be the best in my yellow pages listing, but that would be dishonest, there are better than me in this city, but I don’t charge quite as much.”
That energy is gone. And that’s the point at which capitalism and free enterprise lose the public.
I don’t know, this is a nonsense rant from a non-economist that will no doubt cause a bunch of people to call me an idiot. But it’s not really about economics. It’s really me saying that once upon a time, people didn’t seize their full advantage because it “wouldn’t be right” and people cared a lot about “doing the right thing” and just as importantly, they knew that the “right thing” was not always the “most profitable” thing. This was lost, I think starting with Regan, to market ideology that says that whatever the market does is inherently right, because Adam Smith is god.
That puts capitalism really on the same footing as communism; the world of men ceases to be a space of moral agency and responsibility and is instead just a place where you throw up your hands and say “I don’t have any choice in the matter, it’s all laws of history!”
I’m here to call bullshit on that. And really what this post is all about is just me reflecting on how stupid it is that the most important things I’ve ever done, that contributed the most to society, were the least well compensated, and as a result society lost my labor (and the labor of many others) doing them. Which is dumb. And no, don’t do the thing I just criticized and say “well if you were all that the market would have rewarded you.” Because YouTube is fucking full of worthless streamers who would improve society by dying, yet who are making absolute bank. The market has no morality.
Humans have that.
Well… had that.
So it’s been a long time since I sat in silence and made a blog post in the middle of the day. Maybe even years. Hard to say.
Thing is, there are so many forces mitigating against posting on your own blog these days. Or at least my own blog. As in:
-
I’m a parent with two teens == busy, busy life
-
Work wants 60+ hours a week from me and mostly gets it
-
Almost any platform you use for anything has some sort of chat, commenting, or reviews that eats what you have to say about many things in life
-
Now there’s also AI, with which you end up getting conversational despite yourself
So you don’t really have time to breathe, and then the things you think about your stuff go on Amazon reviews and the things you think about politics go on X or YouTube, and the questions you have and reflections you have are accidentally pounded out into GPT, or Claude, or Gemini, or OpenClaw on local inference (oh yes, I “have” all of the above) because you’re co-working with these things and then it’s like chatting with a co-worker.
And so, at the end of the day, when you finally get a second, your brain is glazed over and inaccessible on the one hand but that’s sort of inconsequential because on the other hand, it’s basically empty.
I don’t exactly know what’s different about today. I think I’m just getting older and grumpier and some of this stuff is starting to break down because I begin to feel like I (and many others) have been fully “virtualized” and I don’t like that. I think the closer you get to your own mortality, the less you like the idea of “virtual you.”
I mean, dead is dead, but data is certainly more dead than, say, a corpse. A corpse at least lays there for a few years. Your immortal soul, if such exists, is eternal. Your physical possessions are good for decades, or even generations in some cases, as long as your offspring see fit to continue to pass them down.
But virtual stuff? Made of bits? Anyone who has worked in software, and then looked back at the last five years of work and realized that unlike many others they’re not building a “body of work” and in fact the things that they have built usually only live for 3-6 months before zapping back out of existence again, understand that a “virtual you” exists in the same way that ClarisWorks or Netscape or the Metaverse exist, which is to say, not at all.
— § —
Meanwhile, on the point of local inference, the weird thing is that now that I have it set up and fully deployed and working well and robustly configured as a systemctl service pointing to LiteLLM as a fellow systemctl service with watchdogging and dashboarding and blah, blah, blah and calling tools and doing research and writing code, I don’t feel like I want to use it for anything.
I have this weird impulse to maybe just put all of it to bed and go outside and make three-legged stools.
I’d love to say that at least the experience was worth something, as in maybe it’s a business model or a useful skill to go and build people out local inference machines with a bunch of stacked GPU cards on PCI-E X16 in Linux with some sort of repeatable deployment package, only despite claims of “shortages” and “supply chain trouble” over the last couple of years the channel is already absolutely full of purpose-built local inference computers that are effectively the next generation of PCs and that already make my local setup with a big fat case and three GPU cards just to get to 76GB VRAM look pretty ridiculous. Hello, Strix Halo and Mac Studio.
Once upon a time I’d have been excited about all of this but now as a person with student loans that I will not pay off within my lifetime who is in the process of prepping to leave SAVE, it all just seems dumb.
The social contract was never really that great, but now it’s pretty much a scam. And, as time has gone on, we’ve gone to this kind of post-linguistic-turn version of The Matrix in which we’re all farmed, yes, but we’re actually being farmed without compensation or freedom for our words, because it is words that power the economy for the billionaires.
But I digress.
— § —
The other thing worth mentioning is that we’re all lonely out here. Funny thing. I have all these friends in my age group, fellow Generation Xers, who I sometimes talk with.
With a single exception, we are all single, we all don’t/won’t date each other, we all regret just how disconnected and isolated everyone has become, how hard it is to make friends, how hard it is to find significant others, and how easy it is in the age of endless consumer life+self customization to arrive at the point at which you basically can’t really get along with other people as anything other than utilities anyway, in the same way that we are utilities for the billionaires.
If we had any guts, we’d all do what the hippies did and carry out the equivalent of a “turn on, tune in, drop out” move, only we apparently don’t have the guts so we all call our friends and talk about how we don’t have any friends with them and bemoan the fact that there’s no one to date and the fact that you can’t really date anyway because it just makes you hate people and realize how much you’re destined to be alone.
This is not the natural state of things. I don’t know whether it’s unique to Generation X, but I think not. From everything I hear, other generations have their versions of the same thing, even if it’s mostly not identical.
People say that social media and technology and wealth inequality have broken the social contract, but in fact what they have broken is us; the social contract’s failure is collateral damage farther down the line, as what a bunch of broken us voted for.
To fix us we would have to kill off half of tech and most of modern convenience and now of course AI, and lose the activist ethos that has basically destroyed everyone and everything, and just quit and be normal and talk to each other like people.
But fucking what?
Be normal and talk to each other like people?
No fucking way, we’d rather die.
— § —
Such is life in 2026. So instead, we’ll still die, but we’ll just do it alone. We’ll only talk to our friends when it doesn’t matter. We’ll only date people so long as we don’t care about them. We’ll only socialize so long as it’s with strangers, around banal, meme-land topics. And we’ll only vote for candidates we don’t respect.
Because this is America, and because we’re all modern, well-educated people.
I am coming to hate my country. This is not a Democrat thing or a Republican thing; they’re roughly the same. It’s just that we hate each other. We all know that we hate each other. Nobody hates Americans so much as Americans do.
It has become intolerable to live here. Everybody’s busy complaining about Trump right now, but the fact is that we long ago crossed the Rubicon; it’s got nothing to do with immigrants or race, really. You can be white and your neighbors can be white and you can be roughly the same class but you hate each other. You hate each other for existing, and you ultimately harass each other, whether directly or through voting or through rumors.
It’s not pleasant to live here. There’s no community. There’s no comity. There’s just hate. And it’s getting worse.
I’m as American as they come. And I’ve traveled internationally. I have no illusions that I will ever be anything other than an American.
But boy do I hate Americans. And they hate me.
We all hate each other.
Rest of the world, don’t be offended. However much you think we hate you, I can assure you that we hate each other more.
Fall was five minutes ago it seems, and yet it’s centuries later. The change in the world at large is obvious to everyone, and the change my small world is just as transformative.
-
I moved wholesale from Mac OS back to Linux
-
I rebuilt my main machine to 76GB VRAM 3x GPU 128GB RAM Core i9
-
I’ve got 3x Thinkcentre m93p minis running NAS and AI agents, all new
-
My job has become about 75% managing AIs
-
And the benefits provider has changed, which transforms 401ks and health and vision and dental and all of that
-
My whole photo workflow has moved from Lightroom to DigiKam + Darktable
-
Dog is old enough now that I’ve returned to working in the home office for the first time in two years
-
Kids are so teenage now that I rarely see them even when they’re here
-
Other switches include: web host 20i -> 101, password manager Lastpass -> 1Password, notes database DevonThink+Joplin -> Obsidian, even boots Blundstone -> Redback
I know all of this will sound minor or obscure to people but the point is: in terms of the minute-by-minute and the weekend-by-weekend, very few things in my life bear any similarity to what they looked like six months ago, and if you go back three years, almost nothing overlaps at all. You never see the rebirth coming until it’s already done.
It is such a wild moment. In some ways, everything old is new again—I was an OG Linux evangelist from 1993 to 2009, and I used to be the guy always on the bleeding edge, and I used to be hosted at 101 from like 2003 to 2023, and I used to wear Redbacks… So there is this weird sense of retro me and/or revival—and yet it’s mixed in with all kinds of crazy new, like father of driving-age teenagers and coding LLM models running on my own metal, which is now in a truly massive case to hold the massive vGPU cards.
This is just a post to placehold an inflection point, in case I wonder about it later.
It was here, and it felt wild, especially with what’s going on in the wider world right now. Who’s unmoored? I’m unmoored!
So that was several posts in a row where I was Eurekaing about figuring out how to finally get ROCm stable, shortly after which… it would break again without warning.
The thing about ROCm that I have now fully internalized is that I don’t understand it, and it may be made in such a way that, or relying on things that, I simply don’t understand. It has periods of meta-stability.
You’ll hunt for new things, new SSDT files, new memory mappings, new kernel parameters, build options, versions, firmware files, etc. And right after a change, it will work!
“AHA!” you say, “I have found the magic thing I was missing. It’s smooth sailing from here on out!”
And it will work all day. Or maybe all week. You might push a couple million tokens through it. And then suddenly, it crashes. And once it has crashed, thereafter it will immediately crash again every time you start it. You’ll swear and wonder why. You’ll be frantic.
“This was just working. I used it all week! What’s changed?! If it was just random crashes that would be one thing, but we went from rock solid all week to it crashes every single start before first turn and I didn’t change a thing!”
You’ll reboot, clear CMOS, do card resets with rocm-smi… and eventually, though it doesn’t make any sense, start hunting for that next “tweak” that must actually be the one that you need.
And hours of searching and experimenting later, you’ll suddenly “find” one that enables you to start again. And not only does it start, but it’s stable! I can ask it to do a task of 50 tool calls and it just rolls! Huzzah!”
Only no. In a day, or a week, it’ll suddenly stop and be unstartable again.
No more, I’m done.
— § —
Previously Vulkan had been rock sold every time, completely no drama, but I’d hesitated to use it because it was about 50% slower than ROCm, which seemed like too much to trade away… better to keep trying until I “figured ROCm out.”
But then I found someone who suggested removing the display card from the devices stack for Vulkan, and when I did… Boom. Not a 50% difference, but about a 5% difference. For no drama. And about 80% less power usage.
I’m sold. I’m Vulkan now on the two v620s and Qwen 3.5 35B A3B q8 (Bartowski). On the RX 6700XT, I’ll throw like a text and a visual embedding model maybe. Simple tools that will be of use.
— § —
Meanwhile, also worth keeping track of: every single Qwen 3.5 template out there is broken for llama.cpp because, it turns out, with Qwen the expectation is that the template does a bunch of fancy things to clean up, but llama.cpp doesn’t support Jinja, only a subset called Minja because until 5 minutes ago that sort of “eh whatevs we’ll do it in template) logic wasn’t really considered viable.
That creates a problem: all the templates are for jinja, but I needed a template for minja (in llama.cpp) so that we could get tool use working properly.
So I had Claude Opus review a bunch of the existing community jinja templates and then pick one to refactor, to the extent possible, for minja.
Here you go: template.jinja
Key and somewhat vexing note, for this to work properly, you also need to to into src/llama-grammar.cpp and change the value of MAX_REPETITION_THRESHOLD from 2,000 to:
#define MAX_REPETITION_THRESHOLD 200000
Because OpenClaw uses like six million parameters for some of its tools and that explodes the grammar enforcer (I still don’t fully understand whether this is a part of minja or not by convention), so once you have a template that actually works instead of breaks, it will seem to be a template that breaks instead of works until you recompile with that constant defined.
— § —
I started all of this nearly two months ago. It’s taken a long time, but we’re finally feeling like we’re getting to the point where I can start to build soon, rather than just be playing with toys.
Leapdragon »
Other Places »
My Favorites »
§ As you get older, the ghosts become more real than anything else.
§ Under the leaves, soil. Under the soil, stone. Under the stone, souls.
§ Radically empowering individuals in society may be the worst mistake we ever made.
§ Want to be a radical? Refuse to suffer. Then, wait for the assault.
§ Goodbye 2017, part two. (The real part.)
§ Sometimes you find home where you’ve never been—and you dwell where you aren’t.
§ The self can’t play Atlas for postmodernity because science is now supernatural.
§ Rehab is universal. So is history.
§ Identity, transcendence, and tactics.
§ Untitled. (a.k.a. Pretty faces, new old photos.)
Regular Reading »
Archives »
May 2026
April 2026
March 2026
February 2026
January 2026
December 2025
July 2025
May 2025
April 2025
February 2025
January 2025
December 2024
October 2024
September 2024
August 2024
July 2024
June 2024
May 2024
April 2024
March 2024
February 2024
January 2024
December 2023
November 2023
October 2023
September 2023
May 2023
April 2023
March 2023
January 2023
December 2022
November 2022
August 2022
June 2022
May 2022
April 2022
March 2022
January 2022
December 2021
November 2021
September 2021
April 2021
March 2021
February 2021
January 2021
December 2020
November 2020
October 2020
September 2020
August 2020
July 2020
June 2020
May 2020
April 2020
March 2020
February 2020
January 2020
December 2019
November 2019
October 2019
September 2019
August 2019
July 2019
May 2019
April 2019
March 2019
February 2019
January 2019
December 2018
November 2018
October 2018
September 2018
August 2018
July 2018
June 2018
May 2018
April 2018
March 2018
February 2018
January 2018
December 2017
November 2017
October 2017
September 2017
August 2017
July 2017
June 2017
May 2017
April 2017
March 2017
February 2017
January 2017
December 2016
November 2016
October 2016
September 2016
August 2016
July 2016
June 2016
May 2016
April 2016
March 2016
February 2016
January 2016
December 2015
June 2015
February 2015
January 2015
December 2014
October 2014
September 2014
August 2014
July 2014
June 2014
May 2014
April 2014
March 2014
February 2014
January 2014
December 2013
November 2013
September 2013
August 2013
July 2013
June 2013
May 2013
April 2013
March 2013
December 2012
November 2012
October 2012
August 2012
July 2012
June 2012
May 2012
March 2012
December 2011
October 2011
September 2011
August 2011
July 2011
June 2011
May 2011
April 2011
March 2011
February 2011
December 2010
November 2010
October 2010
September 2010
August 2010
July 2010
June 2010
May 2010
April 2010
March 2010
February 2010
January 2010
December 2009
November 2009
October 2009
September 2009
August 2009
July 2009
June 2009
May 2009
April 2009
March 2009
February 2009
January 2009
December 2008
November 2008
October 2008
September 2008
August 2008
July 2008
June 2008
May 2008
April 2008
March 2008
February 2008
January 2008
December 2007
November 2007
October 2007
September 2007
August 2007
July 2007
June 2007
May 2007
April 2007
March 2007
February 2007
January 2007
December 2006
November 2006
October 2006
September 2006
August 2006
July 2006
June 2006
May 2006
April 2006
March 2006
February 2006
January 2006
December 2005
November 2005
October 2005
September 2005
August 2005
July 2005
June 2005
May 2005
April 2005
March 2005
February 2005
January 2005
December 2004
August 2004
July 2004
June 2004
May 2004
April 2004
March 2004
February 2004
January 2004
December 2003
November 2003
October 2003
September 2003
August 2003
July 2003
June 2003
April 2003
March 2003
February 2003
January 2003
December 2002
November 2002
October 2002
September 2002
August 2002
May 2002
April 2002
March 2002
February 2002
January 2002
December 2001
November 2001
October 2001
September 2001
July 2001
June 2001
May 2001
April 2001
March 2001
February 2001
January 2001
December 2000
November 2000
October 2000
September 2000
August 2000
July 2000
June 2000
May 2000
April 2000
March 2000
February 2000
January 2000
December 1999
November 1999